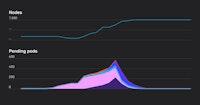
커리어리 친구들, 최근에 OpenAI가 GPT-3, DALL·E 등을 위해서 k8s를 확장한 경험을 블로그에 공유했습니다. 일반적으로 싱글 클러스터를 7500노드 까지 스케일링 하지는 않아서 특별한 관리가 필요하지만, 이렇게 함으로써 간단한 인프라 구조를 가지게 되고, 코드 변경없이도 편하게 확장이 가능하다고 주장했습니다.
아무래도 ML/AI Ops 라고 부르는 OpenAI가 서비스해야 할 API와 환경들이 일반 회사의 환경과는 어플리케이션/하드웨어가 조금 다르므로 GPU가 NVLink/GPUDirect 등을 통해서 노드의 하드웨어를 모두 쓰는 경우가 사실 드뭅니다. 그래서 보통 한개의 Pod가 전체 노드를 차지하기 때문에, 즉 노드가 많지만 스케줄러엔 상대적으로 부담이 적습니다.
네트워킹도 살펴 보면, 포드/노드가 많아져서 Native Pod Networking 으로 전환하고, Alias 기반의 IP 주소처리로 바꿔서 20만개의 IP를 어느때나 사용 가능하다고 합니다. 또한 API 서버는 kube-prometheus 가 제공하는 Grafana 대시보드 사용했고, HTTP 429(Too Many Requests) 와 5xx(Server Error) 를 고수준 문제 시그널로 경고하는게 유용하다고 합니다. 항상 API 서버는 클러스터 외부에서 실행하는 것이 눈길을 끌었습니다.
그 외 현재 MLOps 에서 쿠버네티스 운영이나 구성을 어떻게 할 것인가 고민하는 분들이라면, 한번쯤 봐 볼 필요가 있습니다만 너무라도 큰 환경이기 때문에 실제로 기업들이 이것을 구성하기엔 쉽지 않을 것 같습니다. 참고로 OpenAI는 마이크로소프트와 파트너십을 이용해서 현재 Azure 위에 Managed Kubernetes 가 아니라 K8s 를 서비스 구현했습니다.