제가 애정하는 Chip Huyen이 MLOps 피쳐 플랫폼에 대한 글(https://huyenchip.com//2023/01/08/self-serve-feature-platforms.html)을 썼길래 이번주는 본 내용을 중점적으로 다뤄보겠습니다. 사실 피쳐 플랫폼은 링크드인의 'Feathr'(https://github.com/feathr-ai/feathr) 정도 제외하면 오픈소스로는 전무하며 이제 막 태동하는 단계로 보면 될 것 같습니다.
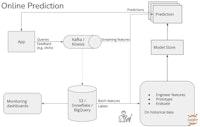
✔️ 기업의 모델 서빙이 일괄 예측에서 온라인 예측 형태로 이동하면서 피쳐 플랫폼 필요성이 대두되었습니다. 온라인 예측의 주된 어려움이라면 레이턴시 문제입니다. 레이턴시는 ① 피쳐 연산 ② 피쳐 레트리벌 ③ 예측 연산의 합으로, 여기서 ③은 많이 연구, 개발된 영역입니다. 피쳐 플랫폼은 ①과 ②를 해결하고자 합니다.
✔️ 요즘에 많이 알려진 피쳐 스토어는 피쳐 플랫폼에 포함되는 개념입니다.
모델 플랫폼의 구성요소는 모델 배포 API, 모델 레지스트리, 예측 서비스 (+ 실험 구성)입니다. 반면에 피쳐 플랫폼의 구성요소는 피쳐 API, 피쳐 카탈로그, 연산 엔진, 피쳐 스토어로 이뤄집니다. 그러니까 피쳐의 단순 보관을 넘어서 집합/스트리밍 연산을 수행하고 전달하는 API를 갖춰야 피쳐 플랫폼인 것입니다.
모델 플랫폼과 달리 비용, 데이터 엔지니어와 데이터 과학자의 협업 문제, 개발 속도 문제로 인해 피쳐 플랫폼은 구축이 어렵습니다.
✔️ 피쳐 유형으로 배치(주로 Spark로 연산), 준실시간(주로 Flink/Spark 스트리밍으로 연산), 실시간(단순 필터링 등)이 있습니다. 현재 기술의 발전으로 준실시간과 실시간 레이턴시 차이는 근소해지고 있습니다.
온라인 예측으로 전환할 때 기업 전략은 보통 2가지입니다. ① 배치 피쳐만 사용하되 온라인 예측을 지원하는 형태로 예측 서비스를 재설계 ② 스트리밍 피쳐를 지원하는 피쳐 플랫폼을 재설계하는 식입니다.
✔️ 스트리밍 피쳐는 만들기 까다롭고 시간이 많이 드는 걸로 악명이 자자합니다. 피쳐 플랫폼의 핵심 과제로 스트리밍 피쳐의 느린 개발 속도 해결을 꼽습니다. 왜 그렇게 개발이 까다로운 걸까요?
✔️첫째, API가 데이터 과학자에게 친숙하지 않습니다. 초기 스트리밍 연산은 Scala 인터페이스를 주로 채택했습니다. 그다음 좀 더 친숙한 SQL이 도입되었습니다. 그러나 SQL은 불충분한 시간 관련 연산 기능, 낮은 코드 재사용성의 문제를 가지고 있었죠. 결국 파이썬 인터페이스로 전환되었고 현재 링크드인과 에어비앤비의 피쳐 플랫폼은 파이썬 피쳐 API입니다. 피쳐 API에 대해 고려해 볼 사항으로 ① (데이터과학자의 주피터 노트북 환경으로 다루기 까다로운) 연속적, 장기간으로 이뤄지는 스트림 피쳐 연산을 어떻게 지원할지 ② 데이터 변환(ETL)과 피쳐화 로직을 어떻게 분리하여 설계할지 등이 있습니다.
✔️ 둘째, 아직 빠른 실험을 위한 기능이 아직 부족합니다. 피쳐 플랫폼은 피쳐/데이터 원천 검색과 데이터 거버넌스 기능을 지원하고 자동화된 백필 기능을 모색하면서 발전하고 있습니다.
Chip Huyen의 책 'Designing ML Systems'(https://www.amazon.com/Designing-Machine-Learning-Systems-Production-Ready/dp/1098107969)는 MLOps의 다양한 개념과 현황, 문제점과 향후 방향을 다루는 명저입니다. 곧 한글로도 번역되어 출간될 예정이니 많이 기대해 주세요.
해당 내용들은 제 Github(https://github.com/youngmki/awesome-aiml-blog)에서 계속 아카이빙 중입니다.