커리어리 친구들, 현대자동차에서 Amazon SageMaker를 이용해서 자율 주행 머신러닝 모델의 학습시간을 단축한 사례를 공유했습니다! 자세한 내용은 다음과 같습니다.
서울에 본사를 둔 현대 자동차는 세계에서 가장 큰 자동차 제조업체 중 하나입니다. 그들은 자율 주행 차라고도 알려진 자율 주행 차를 개발하기 위해 경주에 인적 및 물적 자원을 많이 투자 해 왔습니다.
자율 주행에서 자주 사용되는 알고리즘 중 하나는 객체 클래스로 이미지의 모든 픽셀에 주석을 추가하는 작업인 세그멘테이션입니다. 이러한 클래스는 도로, 사람, 자동차, 건물, 초목, 하늘 등이 될 수 있습니다. 일반적인 개발주기에서 현대 자동차 팀은 정기적으로 정확도를 테스트하고 특정 상황에서 불충분 한 예측 성능을 수정하기 위해 추가 이미지를 수집합니다. 그러나 모델을 교육하고 예정된 기한을 맞추기에 충분한 시간을 남겨 두면서 모든 새 데이터를 준비 할 시간이 충분하지 않은 경우가 많기 때문에 이는 어려울 수 있습니다. Amazon ML Solutions Lab 과 함께 현대 자동차는 확장 가능한 AWS 클라우드 및 Amazon SageMaker를 사용하여 교육을 크게 가속화하여이 문제를 해결했습니다. 데이터 병렬 처리를 위한 새로운 SageMaker 라이브러리를 포함합니다.
솔루션 개요
SageMaker는 분산 컴퓨팅 인프라를 관리하고 트레이닝 작업을 모니터링 및 디버깅하는 "부담 한 작업"을 줄여 고객 문제를 해결하는 완전 관리 형 ML 플랫폼입니다. 이 사용 사례에서는 SageMaker 데이터 병렬 처리 라이브러리와 Amazon SageMaker 디버거 를 사용하여 현대 자동차의 기술적 과제를 해결하고 비용 효율적인 방식으로 비즈니스 목표를 달성합니다.
SageMaker는 데이터 병렬 처리 및 모델 병렬 처리를위한 분산 트레이닝 라이브러리를 제공합니다. 이 경우 학습중인 모델은 단일 GPU의 메모리에 맞지만 학습 데이터의 양이 커서 단일 GPU로 한 세대의 학습이 너무 오래 걸립니다. 이것은 데이터 병렬 분산 학습이 학습 작업의 전체 기간을 줄일 수있는 일반적인 학습 예입니다. SageMaker 데이터 병렬 처리는 트레이닝 데이터를 여러 GPU 인스턴스로 분산하고 할당 된 데이터 세트를 사용하여 각 GPU에서 동일한 모델을 트레이닝함으로써 이를 수행합니다. SageMaker 데이터 병렬 처리 라이브러리는 더 많은 GPU를 사용하면서 거의 선형에 가까운 확장 성을 제공하는 고속 AWS 네트워크 인프라를 활용하도록 설계되었습니다.
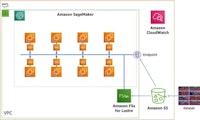
트레이닝 아키텍처는 SageMaker를 사용하고 선택적 으로 데이터 저장을 위해 Luster 용 Amazon FSx를 사용합니다. 우리는 사용 아마존 심플 스토리지 서비스 영구적 인 데이터 저장 등(아마존 S3). PyTorch Data Parallel 기반 교육 코드를 단 몇 줄의 코드만으로 SageMaker 데이터 병렬 처리 라이브러리로 변환하고 8 개의 GPU 인스턴스 또는 총 64 개의 GPU를 사용하여 최대 93 %의 확장 효율성을 달성했습니다. 다음 다이어그램은 분산 교육을 위해 배포 된 AWS 아키텍처를 보여줍니다.
단일 GPU를 사용하여 모델을 훈련하는 것과 달리 다중 또는 분산 GPU 훈련은 단일 GPU에서 관찰되지 않은 기본적인 성능 문제를 나타낼 수 있습니다. 따라서 값 비싼 GPU 리소스를 완전히 활용하고 원하는 모델 성능을 달성하려면 학습 지표와 함께 리소스 사용률을 모니터링하는 것이 중요합니다.
SageMaker 디버거 및 프로파일 링 기능을 통해 딥 러닝 과학자 및 엔지니어는 훈련 작업이 실행되는 동안 시스템 관련 또는 모델 관련 성능 문제를 모니터링, 추적 및 분석 할 수 있습니다. 디버깅 출력을 활성화하기 위해 학습 스크립트의 코드를 변경할 필요가 없습니다. 실시간 모니터링 및 시각화는 Amazon SageMaker Studio 에서 제공 하며 사용자 지정 시각화 또는 분석을위한 API 호출을 통해 수집 된 디버깅 및 프로파일 링 데이터에 액세스 할 수 있습니다. 프로파일 러를 켜거나 끄고 진행중인 학습 작업 중에 프로파일 링 구성을 변경하여 Debugger의 프레임 워크 수준 프로파일 링 기능으로 인한 오버 헤드를 최소화 할 수 있습니다.
SageMaker 데이터 병렬 처리 라이브러리를 사용한 분산 교육
SageMaker 데이터 병렬 처리 라이브러리를 사용하려면 SageMaker DistributedDataParallel클래스를 사용하여 모델을 래핑하고 초기화를 수행 하는 작은 코드 변경 만 필요 합니다. 다음 코드 예제는 이것이 PyTorch 훈련 스크립트에 어떻게 수행되는지 보여줍니다. API의 사용자 경험은 PyTorch의 DistributedDataParallel.
# Importing SageMaker distributed training library
from smdistributed.dataparallel.torch.parallel.distributed import DistributedDataParallel as DDP
import smdistributed.dataparallel.torch.distributed as dist
# Initializing distributed training process group
dist.init_process_group()
# Setting the local rank as the local GPU ID
local_rank = dist.get_local_rank()
# Wrapping the model for distributed training
model = DDP(Net())
torch.cuda.set_device(local_rank)
model.cuda(local_rank)
PyTorch 또는 TensorFlow 분산 학습의 숙련 된 사용자 인 경우 "분산 학습을 위해 클러스터를 설정하는 방법 및 클러스터의 각 인스턴스에서 학습 프로세스를 시작하는 방법은 무엇입니까?"와 같은 질문을 할 수 있습니다. SageMaker에서해야 할 일은 인스턴스 수와 인스턴스 유형을 지정하고 SageMaker가 사용할 분산 교육 전략을 알려주는 것입니다. SageMaker는 무거운 작업을 처리하며이 구성은 PyTorch 및 TensorFlow 모두에 적용됩니다. 다음 예제 코드를 참조하십시오.
estimator = PyTorch(instance_count=4,
instance_type='ml.p4d.24xlarge',
distribution={
'smdistributed':{
'dataparallel':{
'enabled': True
}
}
})
이제 교육 스크립트를 업데이트 했으므로 S3 버킷에있는 데이터 세트에 액세스하는 방법을 결정해야합니다. 가장 일반적인 방법은 훈련 작업이 시작될 때 SageMaker가 S3 버킷에서 연결된 스토리지 또는 내부 NVMe SSD 스토리지로 데이터 세트를 복사하도록하는 것입니다. 이 스토리지는 훈련 작업 전반에 걸쳐 영구적이지 않습니다. 이 방법을 SageMaker 파일 모드라고합니다.
우리의 경우 데이터 세트는 총 300GB이고 파일 수가 많으며 모델 학습을 시작하기 전에 학습 인스턴스로 데이터 복사를 완료하는 데 약 1 시간이 걸립니다. 실제 학습 스크립트는이 단계가 완료된 후에 만 실행됩니다. 데이터로드 시간은 며칠, 몇 주 또는 그 이상이 걸리는 대규모 교육을 수행 할 때 무시할 수 있습니다. 그러나 개발 및 테스트 단계에서는이 시간이 중요합니다.
이로 인해 속도가 느려지는 것을 피하기 위해 다음 조치 중 하나를 취할 수 있습니다.
데이터 세트의 크기 줄이기
데이터를 복사하는 대신 스트리밍하는 SageMaker 파이프 모드 사용Amazon S3에서 데이터를 복사하는 대신 FSx for Lustre를 사용하십시오.
반복 실험을 위해 Lustre에 FSx를 선택했습니다. S3 버킷에있는 데이터를 사용하여 FSx for Luster 파일 시스템을 생성하고 각 교육 작업의 교육 인스턴스에 연결했습니다. FSx for Lustre 파일 시스템은 SageMaker 교육 작업에서 지속되기 때문에 (교육 인스턴스에 연결된 스토리지와 달리) 초기화 지연없이 여러 실험을 실행할 수 있습니다.
코드 변환을 완료하고 훈련 코드가 문제없이 실행 중인지 확인한 후 최적의 I / O 성능을 위해 내부 NVMe SSD 스토리지를 사용할 수 있도록 파일 모드로 전환합니다. 이는 SageMaker 추정기 구성을 변경하여 쉽게 수행 할 수 있습니다. 다시 말하지만 학습 스크립트에 대한 코드 변경이 필요하지 않습니다. 다음 코드를 참조하십시오.
# Using Amazon FSx for Lustre
train_fs = FileSystemInput(file_system_id='file system id',
file_system_type='FSxLustre',
directory_path='/fsx/',
file_system_access_mode='ro')
estimator.fit(inputs={'train': train_fs})
# Using S3
estimator.fit(inputs={'train': 's3://your-bucket-name/prefix/'})
훈련 성능 분석 및 조정
디버거를 사용하기 위해 훈련 코드를 변경할 필요가 없습니다. 디버거는 추정기를 정의 할 때 구성되거나 학습 작업이 실행되는 동안 Studio 또는 Debugger API를 통해 활성화 또는 비활성화됩니다. 훈련 작업 성능을 전체적으로 파악하기 위해 SageMaker 추정기를 통해 CPU 사용률, GPU 사용률, GPU 메모리 사용률 및 I / O 대기에 대한 디버거 시스템 프로파일 링을 500 밀리 초 간격으로 활성화했습니다. 이를 정의 ProfilerConfig하고 추정기에 설정하면 됩니다.
# Setting the local rank as the local GPU ID
local_rank = dist.get_local_rank()
# Wrapping the model for distributed training
model = DDP(Net())
torch.cuda.set_device(local_rank)
model.cuda(local_rank) = ProfilerConfig(
system_monitor_interval_millis=500)
estimator = PyTorch(
...
profiler_config=profiler_config)
디버거에서 Studio의 시각화 기능을 사용하여 시스템 리소스 사용률을 모니터링하여 비정상적인 패턴을 찾았습니다. 단일 GPU 훈련보다 다중 GPU 훈련에서 각 단계에 소요되는 시간이 길어졌습니다. CPU는 다중 GPU 훈련 중에 항상 100 %를 기록했지만 GPU는 충분히 활용되지 않았습니다. 이 패턴은 학습이 진행되는 동안 Studio의 CPU 및 GPU 사용률 히트 맵을 통해 빠르게 식별되었습니다. Python 수준 및 딥 러닝 프레임 워크 수준의 프로파일 링 출력을 제공하는 Debugger의 프레임 워크 프로파일 링 기능을 사용하여 근본 원인 분석을 수행 할 수 있습니다.
Amazon ML Solutions Lab과 Hyundai Motor Company는 디버거 데이터 및 교육 코드를 심층 분석하여 사용자 지정 데이터 로더에서 근본 원인을 찾았습니다. 이 문제는 단일 GPU 교육 컨텍스트에서 성능 오버 헤드를 일으키지 않았습니다. CPU 부족 문제가 해결됨에 따라 시스템 리소스 사용률이 정상으로 돌아 왔고 교육 성능이 향상되었습니다. 이러한 노력으로 동일한 양의 GPU 리소스를 사용하여 다중 GPU 훈련 속도를 두 배로 향상 시켰습니다.
다음 그림은 CPU 및 GPU 사용률 그래프와 히트 맵을 보여줍니다. 왼쪽은 문제가있는 훈련에서, 오른쪽은 수정이 적용된 훈련에서 나온 것입니다.
결론
이 게시물에서는이 복잡한 사용 사례의 과제와 SageMaker 데이터 병렬 처리 라이브러리를 사용하여 교육 속도를 높이는 방법을 자세히 설명했습니다. 또한 병목 현상을 식별하고 훈련 성능을 최적화하기 위해 실제 기술을 공유했습니다. 그 결과 단 5 배 더 많은 인스턴스로 10 배 빠른 훈련 속도를 달성했습니다.
현대 자동차 최진욱 수석 연구원은“우리는 컴퓨터 비전 모델을 사용하여 장면 분할을 수행하는데, 이는 장면 이해에 중요합니다. “예전에는 한 세대 동안 모델을 훈련시키는 데 57 분이 걸렸고 이로 인해 속도가 느려졌습니다. Amazon SageMaker의 데이터 병렬 처리 라이브러리를 사용하고 Amazon ML Solutions Lab의 도움을 받아 5 개의 ml.p3.16xlarge 인스턴스에서 최적화 된 교육 코드로 6 분 만에 교육 할 수있었습니다. 교육 시간이 10 배 단축되었으므로 개발주기 동안 데이터를 준비하는 데 더 많은 시간을 할애 할 수 있습니다. "