[딥러닝의 3가지 미스터리: 앙상블, 지식 증류 그리고 자가 증류 🕵️♂️]
세상에는 진상이나 원인이 밝혀지지 않은 미스터리가 많습니다. 리만 가설이 사실인지, 토마토 유전자가 왜 인간보다 많은지, 사토시 나카모토가 누군지, 내가 술에 취해서 짠 코드가 왜 에러 없이 도는지... 😔 풀리지 않는 의문 투성이죠. 괜찮습니다. 세상사 원래 불명확한 토대 위에서 굴러가는 법이니깐요. 딥러닝은 탁월한 성능을 자랑하지만 작동 원리에 관한 이론적 기초를 이제 막 쌓아가는 실정입니다. 그중 흥미로운 영역으로 앙상블, 지식 증류 그리고 자가 증류를 꼽을 수 있겠죠.
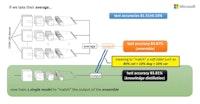
교수님 앞에서 발음하면 스트레스가 풀리는 데이터셋, CIFAR-100에 대해 WiderResNet-28-10 아키텍처로 학습합니다. 다른 조건 변경 없이 무작위 시드 값으로 10번 훈련하면 테스트 정확도 평균 81.51%, 표준편차 0.16%로 성능이 무척 안정적으로 나옵니다. (1) 이때 1개 모델 대신 10개 모델 출력 값을 평균 내어 분류하면 정확도가 84.87%로 향상됩니다. 잘 알려진 앙상블 기법이죠. (2) 앙상블은 추론 시간이 오래 걸립니다. 그래서 나온 게 지식 증류 기법입니다. 앙상블 출력과 일치하도록 단일 모델을 훈련시킵니다. 즉 실제 레이블 "트와이스 사나"를 사용하는 게 아니라 앙상블 출력 값인 “트와이스 사나 80%, 시바견 20%”로 훈련시킵니다. 😔 그러면 1개 모델로 앙상블에 준하는 정확도를 만들 수 있습니다. (3) 자가 증류는 더 놀랍습니다. 앙상블이 아닌, 단일 모델에 대해서 지식 증류 기법을 수행해도 정확도가 향상됩니다. 앙상블, 지식 증류 그리고 자가 증류 같은 현상은 왜 벌어지는 걸까요?
위 예시는 모델마다 동일한 데이터셋과 아키텍처를 사용하므로 Bagging이나 Random Forest의 상황과는 다릅니다. 가설을 세워봅시다. 신경망의 특정 가중치는 무작위로 주어진 초기값에 매우 가깝게 남아있을 것이고 그를 통해 결정되는 피쳐 부분집합에 크게 의존하여 결괏값을 매핑할지 모릅니다. 그래서 여러 모델을 결합하면 유효한 피쳐 개수가 증가하므로 성능이 향상하는 걸까요? 아니면 고전적 통계 이론처럼 개별 모델 분산이 평균을 통해 감소하면서 성능이 향상하는 걸까요? 아래 소개할 논문은 두 가설 모두 증거로 채택하기 어렵다고 다양한 실험을 통해 얘기합니다. 특히나 지식 증류 같은 현상은 설명이 잘 안돼요.
지난 12월 MS는 딥러닝 앙상블 기법의 이론적 근거가 되는 논문 "Three mysteries in deep learning: Ensemble, knowledge distillation, and self-distillation"을 발표했습니다. 쉽게 얘기해보죠. 컴퓨터 비전 데이터셋에서 모델은 객체를 여러 관점을 통해 분류해낼 수 있습니다. 예를 들어, 자동차 이미지를 헤드라이트, 바퀴 또는 창문의 특징을 보고 분류할 수 있어요. 신경망은 무작위 시드 값에 따라 이러한 관점 중 일부 집합만 빠르게 학습하여 클래스를 분류합니다. 즉 모델이 헤드라이트 하나만 사용해서 자동차를 분류해도 정확도 면에서 충분할 수 있어요. 물론 일부 사진은 각도 때문에 자동차 헤드라이트가 보이지 않을 수 있습니다. 여기서 앙상블이 큰 힘을 발휘합니다. 개별 신경망들이 각자 다른 관점으로 특징을 학습, 객체를 분류하기 때문에 이것들을 합치면 종합적인 판별이 가능하겠죠. 이러한 설명을 지식 증류에도 적용할 수 있습니다. 일부 자동차 이미지의 헤드라이트는 고양이 눈처럼 보일 수 있습니다. 이 경우 앙상블 모델은 자동차 이미지가 약 10%의 확률로 고양이와 비슷하다고, 헤드라이트 패턴에 주목하라고 출력 값을 통해 알려줄 수 있죠. 다시 말해 개별 모델은 지식 증류 과정을 통해 앙상블 모델이 갖는 종합적인 관점으로 판별하게끔 학습을 강제당하는 셈입니다. 자기 증류의 과정 또한 이와 비슷합니다.
제가 유비 추리로써 비약적인 설명을 했지만 논문은 사실 수리적인 증명을 담고 있습니다. 딥러닝의 이론적인 기초를 쌓으려는 노력은 점차 증가하고 있어요. 몇 년 후 우리는 기계공학처럼 딥러닝의 작동 원리를 좀 더 투명하게 이해하는 세계에 살고 있을지도 모르겠네요.